
목록Algorithm/Algorithm (20)
:: ADVANCE ::
[STL] vector 생성자vector vvector v(n) : 초기화된 n개의 원소를 가진 vectorvector v(n, x) : x로 초기화된 n개의 원소를 가진 vectorvector v(v2) : v2 복사본. (복사 생성자 호출) vector v(b, e) : 반복자 구간 [b, e)로 초기화된 원소를 가진 vector 멤버 함수v.assign(n, x) : x값으로 n개의 원소를 할당v.assign(b, e) : 반복자 구간 [b, e)로 할당v.clear() : 모든 원소를 제거q = v.erase(p) : p가 가리키는 원소를 제거. q는 다음 원소를 가리킴q = v.insert(p, x) : p가 가리키는 위치에 x값을 삽입한다. vector의 size()는 unsigned int ..
[STL] 어댑터 어댑터는 구성 요소의 인터페이스를 변경한다.일반 컨테이너(반복자나 함수)를 기반으로 특수(특정한 기능을 가진) 컨테이너(반복자나 함수)를 제공하는 느낌? * 컨테이너 어댑터 (container adaptor) : stack, queue, priority_queue* 반복자 어댑터 (iterator adaptor) : reverse_iterator, back_insert_iterator, front_insert_iterator, insert_iterator* 함수 어댑터 (function adaptor) : 바인더(binder), 부정자(negator), 함수 포인터 어댑터(adaptor for pointers to functions) stack 대표적인 컨테이너 어댑터일반 컨테이너를 L..
[STL] 알고리즘 find 알고리즘은 순방향 반복자를 요구vector v;vector::iterator iter;iter = find(v.begin(), v.end(), 20); // v [begin, end) 중에서 원소 20을 찾아 그에 해당하는 반복자를 반환 sort 순차열을 정렬하는 알고리즘임의 접근 반복자를 요구한다. (vector, deque) sort(정렬을 원하는 시작점, 끝점(끝 원소 다음), 정책); vector v;sort(v.begin(), v.end()); int arr[n];sort(arr, arr + n); 함수 객체STL 알고리즘은 함수 객체, 함수, 함수 포인터 등의 함수류를 인자로 받아 알고리즘을 유연하게 동작시킨다.따라서, STL에서 함수 객체는 클라이언트가 정의한 동..
[STL] STL Standard Template Library프로그램에 필요한 자료구조와 알고리즘을 템플릿으로 제공하는 라이브러리.자료구조와 알고리즘은 서로 반복자라는 구성 요소를 통해 연결한다. STL의 구성 요소* 컨테이너 (Container) : 객체를 저장하는 객체로 컬렉션 혹은 자료구조라도 한다.* 반복자 (Iterator) : 포인터와 비슷한 개념으로 컨테이너의 원소를 가리키고, 가리키는 원소에 접근하여 다음 원소를 가리키게 하는 기능을 한다.* 알고리즘 (Algorithm) : 정렬, 삭제, 검색, 연산 등을 해결하는 일반화된 방법을 제공하는 함수 템플릿이다.* 함수 객체 (Function Object) : 함수처럼 동작하는 객체로 operator() 연산자를 오버로딩한 객체이다. 컨테이너..
[Binary Search] 이진 탐색 이진 탐색 Binary Search (이분 탐색이라고도 한다.) 이진 탐색은 순차 탐색과 달리 모든 경우를 다 탐색하지 않습니다.이진 탐색이란 한번 비교를 거칠 때 탐색 범위를 반으로 줄여가며 탐색을 하는 방법입니다.따라서 이진 탐색의 시간 복잡도는 O(logN)입니다. 이진 탐색의 경우 조건은 앞으로의 탐색 과정을 보면 알겠지만, 값이 정렬되어 있어야 한다는 것이다.배열에 값이 저장되어 있던, 어떤 특정한 값을 찾던지 간에 탐색해 가는 과정에서 범위를 줄이기 위해서는 정렬을 통해 더이상의 가능성이 존재하지 않는다는 보장이 되어 있어야 하기 때문이다. 이진 탐색의 탐색 과정 245791012152125 위와 같이 정렬된 배열에서 이진 탐색 알고리즘을 적용하여 데이터..
 [Algorithm][math] 소수, 에라토스테네스의 체
[Algorithm][math] 소수, 에라토스테네스의 체
[Algorithm][math] 소수, 에라토스테네스의 체 소수 (prime)약수가 1과 자기 자신 밖에 없는 수 (1은 소수가 아니다) n이 소수가 되려면, 2보다 크거나 같고, n - 1보다 작거나 같은 자연수로 나누어 떨어지면 안된다. 1234567891011bool isprime(int n){ int i; if(n 소수가 아닌경우 이미 앞에서 배수를 돌면서 i의 배수 또한 0이 되기 때문에 배수를 탐색할 필요가 없다. * i가 배열의 범위나 자료형의 범위를 넘지 않도록 주의한다. 123456789101112131415int prime[1001]; void checkprime(){ int i, j; for (i = 2; i
[Floyd] 플로이드 알고리즘 (graph 최단거리 알고리즘) 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162#include #define SIZE 101#define INF 1000 int graph[SIZE][SIZE];int floyd[SIZE][SIZE]; void init() { int i, j; for (i = 0; i
 [Heap Sort] 힙 정렬
[Heap Sort] 힙 정렬
[Heap Sort] 힙 정렬 힙 정렬은 상당히 효율적인 정렬 알고리즘을 선택 정렬과 유사한 접근 방식을 가졌다. 퀵소트는 대부분의 경우에서 최상위의 성능을 내기 때문에 힙 정렬은 이에 비해 열세이지만,힙소트는 최악의 경우에도 O(NlogN)을 보장한다. 힙 소트는 두가지 단계로 나누어 볼 수 있다. 1. Heap Tree 구성2. 다시 정렬을 하면서 Tree 수정 트리를 수정할 때 가장 상위 노드의 값과 가장 마지막 노드의 값을 교환하여마지막 부터 채워나간다.하지만 이는 알고리즘을 응용하면 처음부터 채워나갈 수 있지 않을까 싶다. 트리와 배열을 그림으로 그려서 표현하고 싶으나 그거까지는 귀찮.... 코드를 구현할 때 참고한 블로그에 그림과 설명이 친절하게 되어있다.이를 참고해서 공부하면 좋을 것 같다...
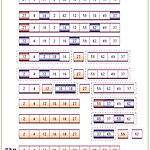 [Quick Sort] 퀵 정렬
[Quick Sort] 퀵 정렬
[Quick Sort] 퀵 정렬 12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364#include int count; void print(int *data, int size){ int i; for (i = 0; i left) { while (data[left] pivot) { quicksort(data, pivot + 1, end); }} int main(void){ int n, i; int input[100]; scanf("%d", &n); for (i = 0; i
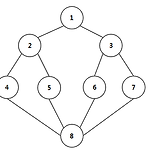 [DFS] 깊이 우선 탐색 (Depth First Search)
[DFS] 깊이 우선 탐색 (Depth First Search)
깊이 우선 탐색 (Depth First Search) 탐색알고리즘으로는 깊이 우선 탐색(DFS : Depth First Search)과 너비 우선 탐색(BFS : Breath First Search)이 있다. 깊이 우선 탐색(이하 DFS)은 일반적으로 구현할 때는 스택(stack)을 이용하고,트리나 그래프 같은 자료구조에서 데이터를 탐색할 때 사용하는 알고리즘이다. DFS 알고리즘은 더이상 나아갈 길이 보이지 않을 만큼 깊이 찾아가면서 탐색한다.만약, 나아갈 길이 존재하지 않으면 이전의 위치로 돌아와 찾아가지 않은 다른 길로 뻗어 나가면서 탐색해 나간다. 그래프를 보면 숫자가 있는 원은 정점(Vertex)라고 하고, 정점과 정점을 잇는 연결선을 간선(Edge)이라고 한다. 이제 위 그래프를 DFS를 이용..